Derribando mitos de Google y el SEO con JavaScript
En la comunidad de SEO, el uso de JavaScript siempre ha sido un tema controvertido, en gran parte por la percepción de que Google tiene dificultades para renderizar y rastrear sitios con mucho JavaScript. Sin embargo, una reciente investigación de Vercel, en colaboración con la consultoría MERJ, desmintió varios mitos populares relacionados con el SEO y el uso de JavaScript. A continuación, exploraremos estos mitos y veremos cómo la realidad ha cambiado gracias a los avances en las capacidades de renderizado de Google.
Comprender cómo los motores de búsqueda rastrean, procesan e indexan las páginas web es fundamental para optimizar los sitios web y mejorar su visibilidad en los resultados de búsqueda. Con el paso de los años a medida que los motores de búsqueda como Google cambian sus procesos, resulta difícil hacer un seguimiento de lo que funciona o lo que no, especialmente con JavaScript del lado del cliente.
Los mitos que se trabajaron en la investigación de Vercel con MERJ son los siguientes:
- “Google no puede renderizar JavaScript del lado del cliente”.
- “Google trata las páginas JavaScript de forma diferente”.
- “La cola de renderizado y el tiempo inciden significativamente en el SEO”.
- "Los sitios con mucho JavaScript tardan más en ser rastreados."
Un punto importante a mencionar es que en la actualidad, desde 2018, Google tiene capacidades de renderizado modernas, con una versión actualizada de Chrome para la renderización, que se mantienen al día con las últimas tecnologías web.
Los aspectos claves del sistema actual incluyen:
- Representación universal: Google ahora intenta representar todas las páginas HTML, no solo un subconjunto.
- Navegador actualizado: Googlebot utiliza la última versión estable de Chrome/Chromium, compatible con las funciones JS modernas.
- Representación sin estado: cada representación de página se realiza en una nueva sesión del navegador, sin conservar las cookies ni el estado de las representaciones anteriores. Por lo general, Google no hará clic en elementos de la página, como contenido con pestañas o banners de cookies.
- Enmascaramiento: Google prohíbe mostrar contenido diferente a los usuarios y a los motores de búsqueda para manipular las clasificaciones. Evite el código que altere el contenido en función de
User-Agent. En su lugar, optimice la representación sin estado de su aplicación para Google e implemente la personalización a través de métodos con estado. - Almacenamiento en caché de activos: Google acelera la representación de páginas web mediante el almacenamiento en caché de activos, lo que resulta útil para páginas que comparten recursos y para la representación repetida de la misma página. En lugar de utilizar
Cache-Controlencabezados HTTP, el Servicio de representación web de Google emplea su propia heurística interna para determinar cuándo los activos almacenados en caché siguen siendo nuevos y cuándo es necesario volver a descargarlos.
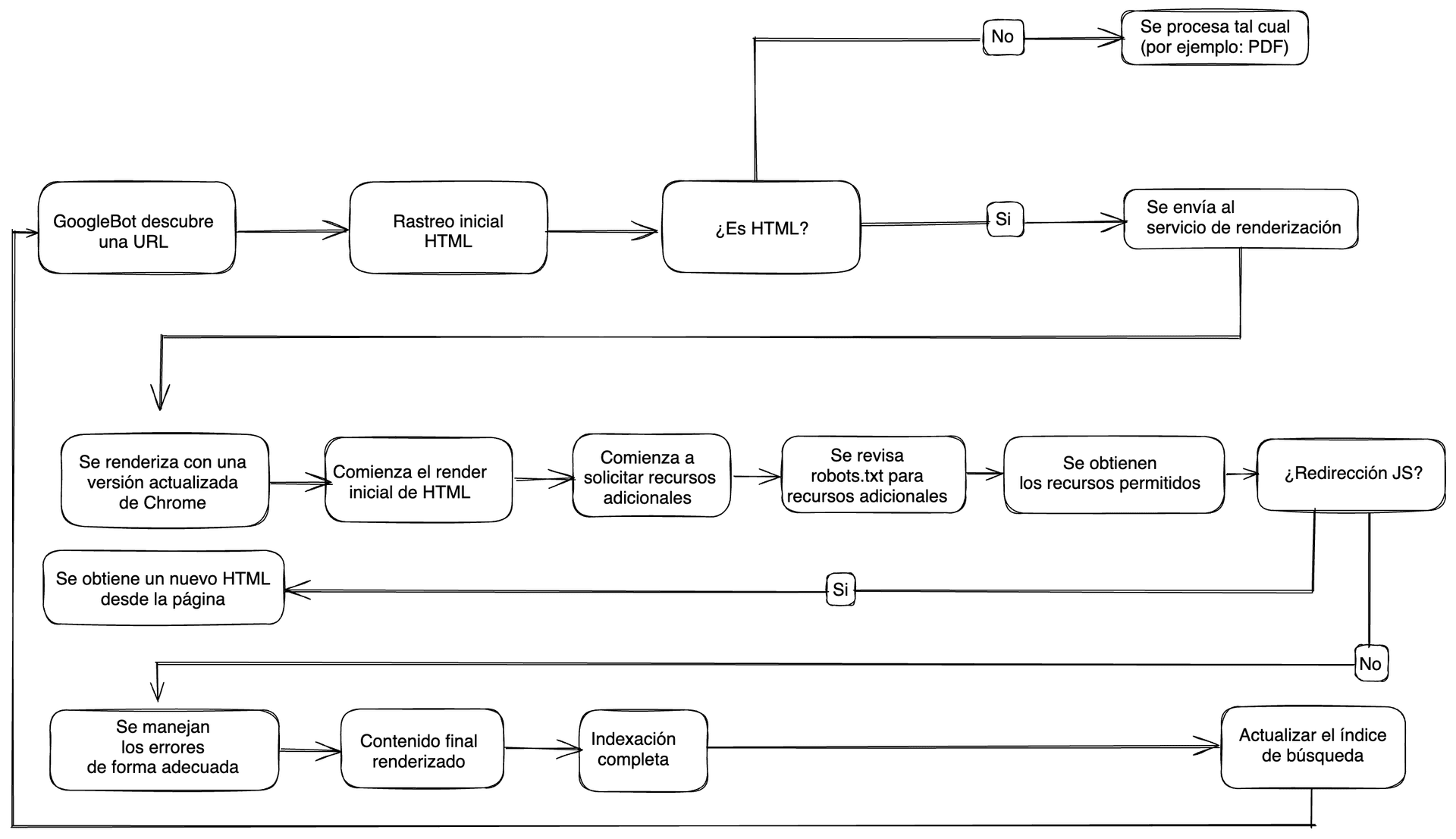

¿Qué metodología se usó para desmentir los mitos?
Se realizó un estudio utilizando la infraestructura de Vercel y la tecnología Web Rendering Monitor (WRM) de MERJ. La investigación se centró en nextjs.org, con datos complementarios de monogram.io y basement.io, que abarcan desde el 1 de abril hasta el 30 de abril de 2024.
Se implementó un middleware Edge personalizado para interceptar y analizar las solicitudes de rastreadores de motores de búsqueda. Este proceso permitió identificar y rastrear estas solicitudes sin involucrar datos de usuarios. Además, se inyectó una biblioteca JavaScript ligera en las respuestas HTML enviadas a los bots. Esta biblioteca, una vez que la página terminaba de renderizarse, enviaba información clave como la URL, un identificador único y una marca de tiempo al servidor para hacer un seguimiento de la renderización.
Análisis de datos
Compararon las solicitudes iniciales del servidor con los datos enviados por el middleware a un servidor externo para confirmar qué páginas fueron renderizadas, calcular el tiempo entre el rastreo inicial y la renderización completa, y analizar cómo Googlebot procesó diferentes tipos de contenido.
Alcance de los datos
El análisis se centró en más de 37.000 páginas renderizadas por Googlebot, proporcionando un conjunto sólido de datos. Aún se están recopilando información de otros motores de búsqueda y proveedores de IA, como OpenAI y Anthropic, para estudios futuros.
Vamos a los mitos
Mito 1: "Google no puede renderizar contenido en JavaScript"
Este es quizás el mito más común. Durante mucho tiempo se pensó que Google no podía procesar correctamente las páginas que dependen de JavaScript. Esto llevó a muchos desarrolladores a evitar el uso de frameworks JS o a implementar soluciones complicadas para el SEO.
Realidad: Hoy en día, Google utiliza una versión moderna de Chrome para renderizar todo el contenido de las páginas, incluyendo JavaScript. En la investigación realizada por Vercel, se analizaron miles de solicitudes de Googlebot y se encontró que el 100% de las páginas con contenido generado por JavaScript fueron renderizadas correctamente. Esto incluye frameworks modernos como Next.js, que dependen tanto del renderizado del lado del servidor (SSR) como del cliente.
Mito 2: "Google trata las páginas con JavaScript de manera diferente"
Se pensaba que Google aplicaba criterios distintos para las páginas que utilizan JavaScript, lo que afectaba negativamente su clasificación en los resultados de búsqueda. La preocupación era que las páginas JS se enfrentarían a un rastreo o indexación diferente a las páginas HTML estáticas.
Realidad: La investigación de Vercel demostró que Google trata las páginas JavaScript de la misma manera que las páginas HTML estáticas. Esto significa que no hay ninguna penalización inherente para las páginas que dependen de JS. Durante los tests realizados, no se encontraron diferencias significativas en la forma en que Google renderiza o rastrea páginas con distintos niveles de complejidad de JavaScript.
Mito 3: "La cola de renderizado y el tiempo impactan significativamente en el SEO"
Otro mito común es que el tiempo que tarda Google en renderizar una página con JavaScript tiene un impacto negativo en su clasificación en los resultados de búsqueda, debido a una supuesta larga cola de renderizado.
Realidad: Aunque existe una cola de renderizado, su impacto es mucho menor de lo que se pensaba. En la investigación de Vercel, se encontró que la mayoría de las páginas son renderizadas por Google dentro de los primeros minutos de ser rastreadas. El 50% de las páginas fueron renderizadas en menos de 10 segundos, y solo un pequeño porcentaje enfrentó retrasos mayores. Además, el estudio mostró que la complejidad del JavaScript no influye directamente en los tiempos de renderizado de Google.
Mito 4: "Los sitios con mucho JavaScript tienen un descubrimiento de páginas más lento"
La idea de que los sitios pesados en JavaScript tienen un descubrimiento más lento de sus páginas ha sido una preocupación recurrente, especialmente para sitios de una sola página (SPAs) que dependen en gran medida de la carga dinámica de contenido.
Realidad: Google puede descubrir enlaces en contenido generado dinámicamente de manera eficiente. Según el análisis de Vercel, Google fue capaz de rastrear e indexar tanto los enlaces en HTML estático como los encontrados en contenido generado por JavaScript. Si bien es cierto que el contenido renderizado del lado del servidor puede ser descubierto ligeramente más rápido, la diferencia es mínima. Además, el uso de un sitemap bien configurado puede eliminar prácticamente cualquier diferencia en el tiempo de descubrimiento.
Implicaciones y Recomendaciones
Compatibilidad con JavaScript: Google puede renderizar e indexar sin problemas incluso aplicaciones JS complejas como las SPA.
Paridad de renderizado: No hay diferencias sustanciales entre cómo Google trata las páginas JS frente a las páginas HTML estáticas.
Cola de renderizado: Si bien existe una cola de renderizado, la mayoría de las páginas se renderizan en minutos. Los sitios con mucho JavaScript no sufren grandes retrasos en el descubrimiento.
Rendimiento y presupuesto de rastreo: El renderizado de JavaScript es más costoso para Google que el HTML estático, lo que afecta el presupuesto de rastreo en sitios grandes. Optimizar el rendimiento, reducir el JS innecesario y priorizar el SSR o ISR puede mejorar la eficiencia del rastreo.
Recomendaciones clave:
- Aprovecha los frameworks JavaScript: Usa frameworks como Next.js para construir aplicaciones modernas sin preocuparte por el SEO.
- Elementos SEO críticos: Usa renderizado del lado del servidor (SSR) para etiquetas y contenido importante en el HTML inicial.
- Gestión de recursos: Asegúrate de que los recursos clave no estén bloqueados por archivos como
robots.txt. - Estructura de enlaces: Usa enlaces HTML estándar para la navegación y facilita el rastreo de Google.
- Sitemaps: Mantén los sitemaps actualizados para mejorar el descubrimiento y la indexación de páginas.
Conclusión
La investigación de Vercel y MERJ ha aclarado muchos de los malentendidos comunes sobre cómo Google maneja JavaScript. Los desarrolladores ahora pueden construir aplicaciones modernas con JavaScript sin preocuparse por el SEO, siempre que sigan las mejores prácticas de optimización, como el renderizado del lado del servidor y el uso eficiente de recursos. Con estos avances, Google puede rastrear, renderizar y descubrir contenido dinámico de manera efectiva, permitiendo a los sitios con mucho JavaScript competir en igualdad de condiciones con sitios HTML estáticos.